
I think I figured out exactly how the “AI uses a bottle of water per prompt” miscalculation happened
Looks like it's roughly 50-250x too high

Update
After writing this, Shaolei Ren reached out to me with some clarifications for how the estimate was made. While I can’t share everything, I do now have access to the EcoLogits methodology where he got the number. A lot of the information here was my best guess but turned out to be incorrect. I’ll circle back on this post with an update on what actually happened once I’ve had time to work through the methodology. Importantly, Ren, the person who came up with the “ChatGPT uses a bottle of water per prompt” estimate, now agrees that while this was a reasonable estimate at the time, the actual water cost of GPT-4 was likely much lower, at around 15 mL per prompt, and only 5 mL in the data center itself, as opposed to a 500 mL bottle of water, and since then AI models have become much more energy and water efficient. So no one researching this, including the person who came up with the original statistic, actually believes that chatbots use a whole bottle of water per prompt anymore. This statistic needs to go away. The actual cost of a chatbot prompt is about ~200 times lower.
I’ll update this with the full story once I have time.
Intro
The most widespread misconception about AI and the environment is that each prompt uses a whole bottle of water. This came from this Washington Post article, which opened with this graphic.
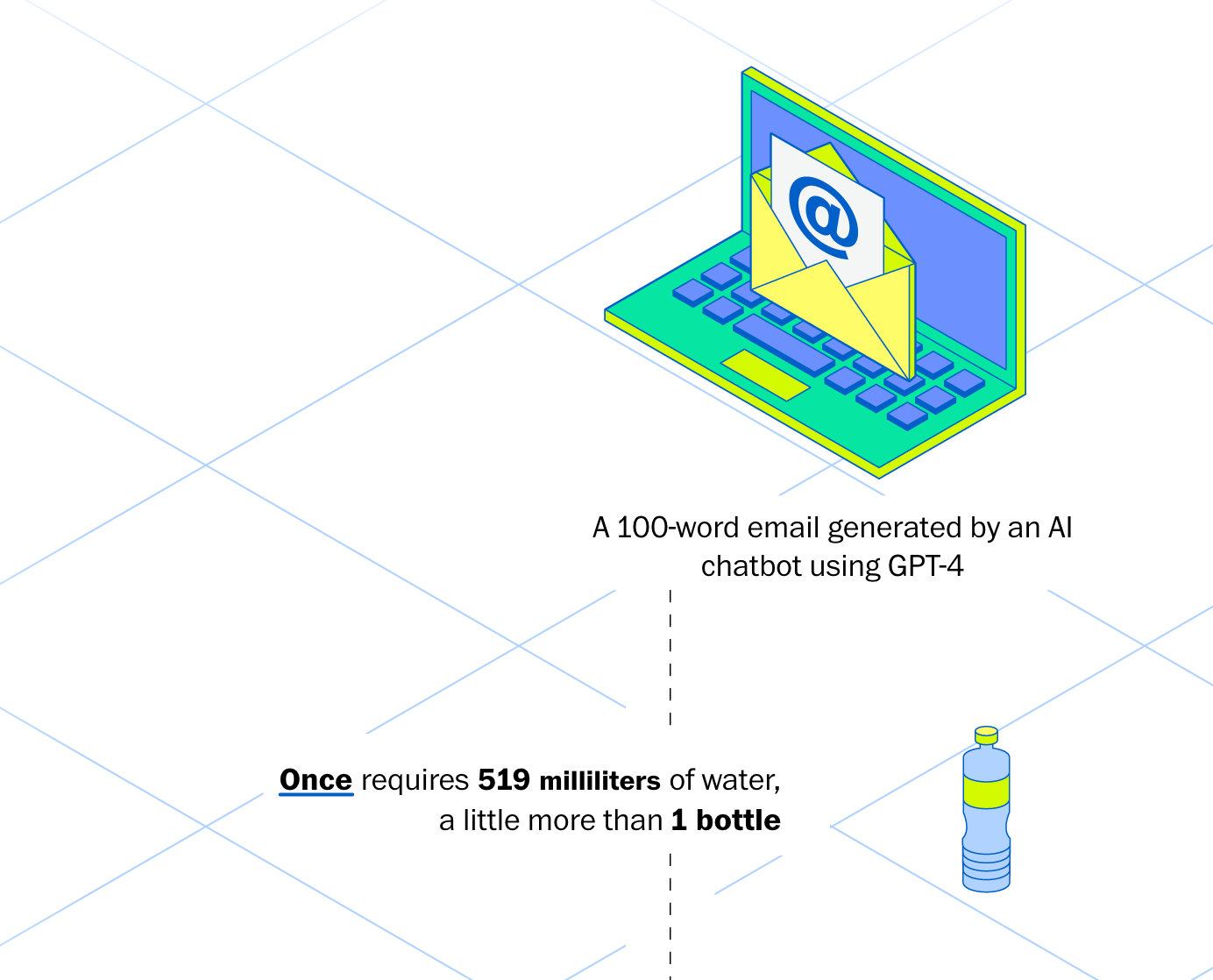
The authors explained that they got these numbers from Shaolei Ren, an assistant professor of electrical and computer engineering at UC Riverside. Specifically:
Water and electricity costs were calculated by Ren for ChatGPT-4 at an average American data center.
Ren had previously done a study on GPT-3 where he and a team had estimated that about 10-50 prompts would add together to cost a whole bottle of water. Here, his estimate for GPT-4 was about 30 times larger. How did this happen?
Ren never explained how he got this number, but I might have figured out exactly how it happened. To understand, you first need to know a few things about his study “Making AI Less Thirsty” because he plugged a new energy value for GPT-4 into the same methodology for had used for GPT-3. Once you fully understand what happened, it becomes hard not to think:
This was a napkin math estimate that didn’t account for pretty simple things we knew about what GPT-4 was probably like, or AI hardware. It shouldn’t have been allowed to have basically any influence over the discourse or get written up as an infographic in a major newspaper.
It’s about 50-250 times too high, not even accounting for the fact that many people misunderstood to mean all this water is used in data centers themselves.
Making AI Less Thirsty
The goal of this paper was to estimate how much water AI uses, both for training and per prompt. To get the total water cost, the researchers included both the water consumed onsite in data centers and offsite in the power plants generating the electricity. This table has their findings:
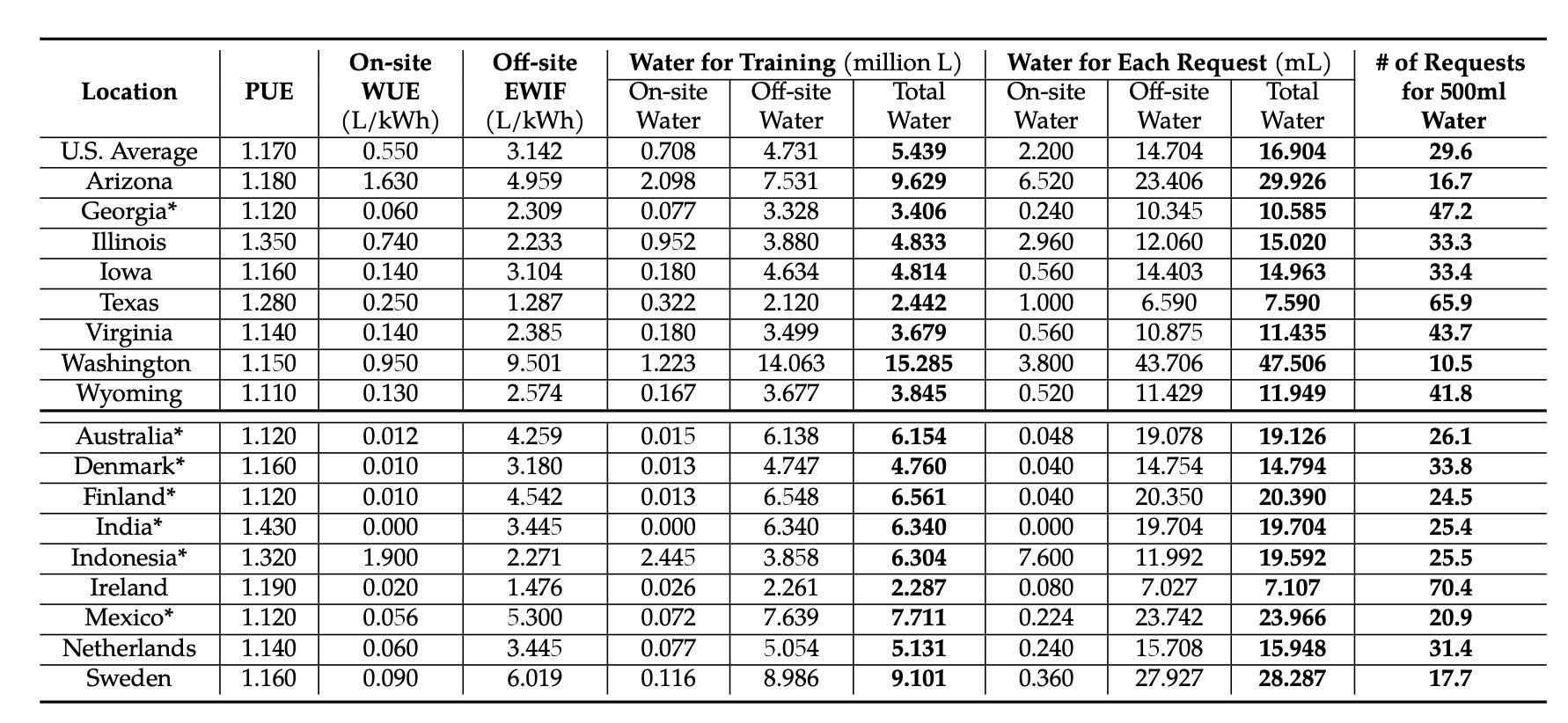
Explaining the columns one at a time:
“PUE” is the “power usage effectiveness” of a data center: a measurement of how much power is wasted by dividing total power going in by the power finally delivered to chips. If 5 units of power go into a data center, and 1 is lost to heat before getting to the chips, the PUE will be 5/4 = 1.25.
Onsite WUE is the water usage effectiveness, how many liters of water are used to cool chips per kilowatt hour of energy used.
Offsite EWIF is the “Energy-Water Intensity Factor” or how much water is consumed generating the electricity at the power plant offsite. So according to the table, the average kilowatt-hour of energy in the US consumes 3.142 liters of water to generate.
So the formula here is pretty simple. Take the energy cost of a prompt in a data center, and multiply it by [onsite water cost of cooling per unit energy + offsite water cost of generating the energy] and you get the full cost of a prompt. The original study was looking at GPT-3 and estimated that it used on average about 4 Wh per prompt.
Three key things to notice about this table:
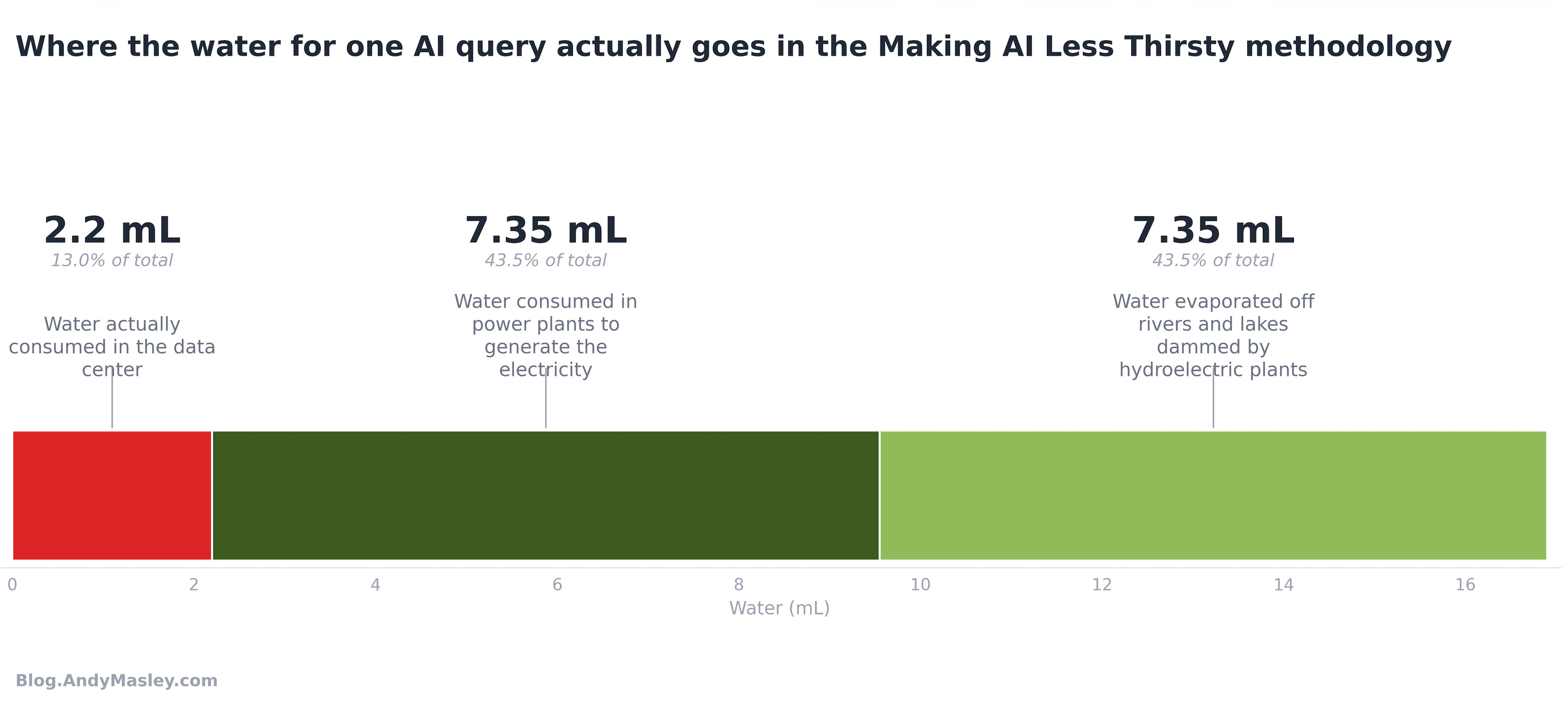
The offsite water cost used to generate electricity makes up the vast majority of the water used on AI prompts everywhere. Most of the cost here is not happening in the data center itself.
A few states have absurdly high water costs, especially Washington. Why is that one so high? About 65% of Washington’s electricity comes from hydroelectric plants. All of the water measured to be “consumed” by those plants is actually water evaporated off the surface of lakes and rivers dammed by them. Importantly, this exact same amount of water would evaporate regardless of whether the data center drew water from the plant, and it’s vastly preferable that Washington use hydroelectric power instead of fossil fuels. This is a weird but common addition to the “water cost of an AI prompt.” Taking out this evaporated water would reduce the “cost of an AI prompt” in Washington State from 47.5 mL to about 5.5 mL (because so much water is evaporated off lakes compared to the water evaporated by other power plants). Altogether, roughly 50% of the US grid’s consumptive water cost per kWh is water evaporated by dammed lakes and rivers that would probably still be dammed regardless of whether data centers drew from them, so that’s about 50% of the offsite water cost per prompt. The authors make it clear that they’re including this water as part of the cost.
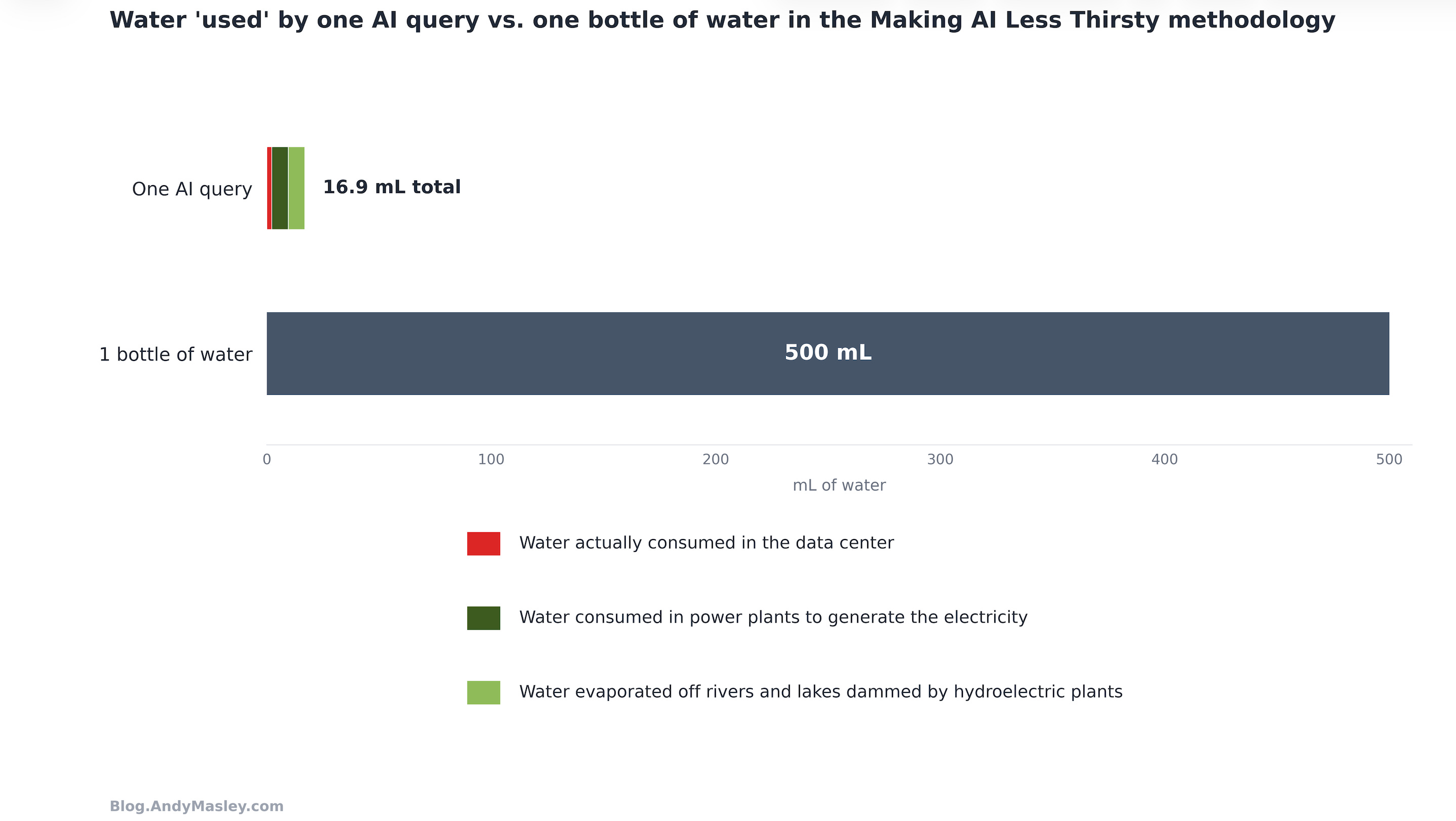
The average water cost of a prompt in the US in the data center itself (onsite) is 2.2 mL. 1/227th of a 500 mL bottle of water.
So the full water cost of an AI prompt looks like this:
Here it is compared to a bottle of water:
How I think Ren got his estimate for the Washington Post article
Why did the water cost jump so much?
The Washington Post article was published a year and a half after the original preprint of the study, on September 18th 2024.
Unlike previous coverage of AI’s per prompt water cost, this article is focused on GPT-4 rather than 3. Previous articles had used Ren’s numbers from his study to say that 10-50 AI prompts use a bottle of water. This one claims that now with GPT-4, it takes just a single short prompt to use a whole bottle of water. Just generating 100 words.
The authors say they’re assuming a single GPT-4 query uses 140 Wh of energy. 35 times more than Ren’s estimate of 4 Wh for GPT-3.
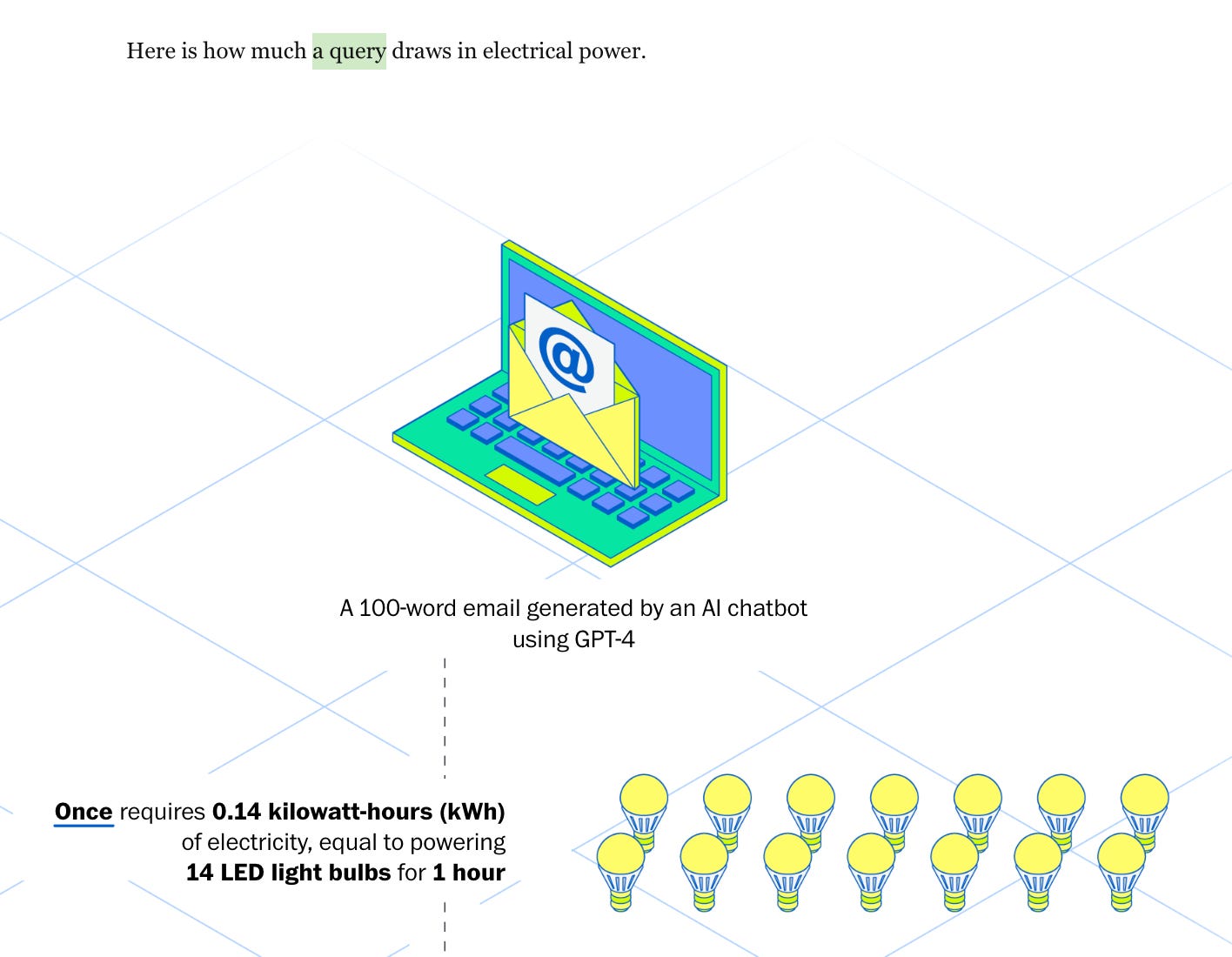
So the reason the water cost grew so much from ChatGPT-3 to 4 is that Ren’s using the same methodology, but plugging in 140 Wh instead of 4 Wh. This massively increases the water cost per prompt, because both onsite water used to cool servers and offsite water used to generate electricity scale linearly with energy used. The water numbers the Washington Post gives are equal to the original numbers multiplied by about 30.
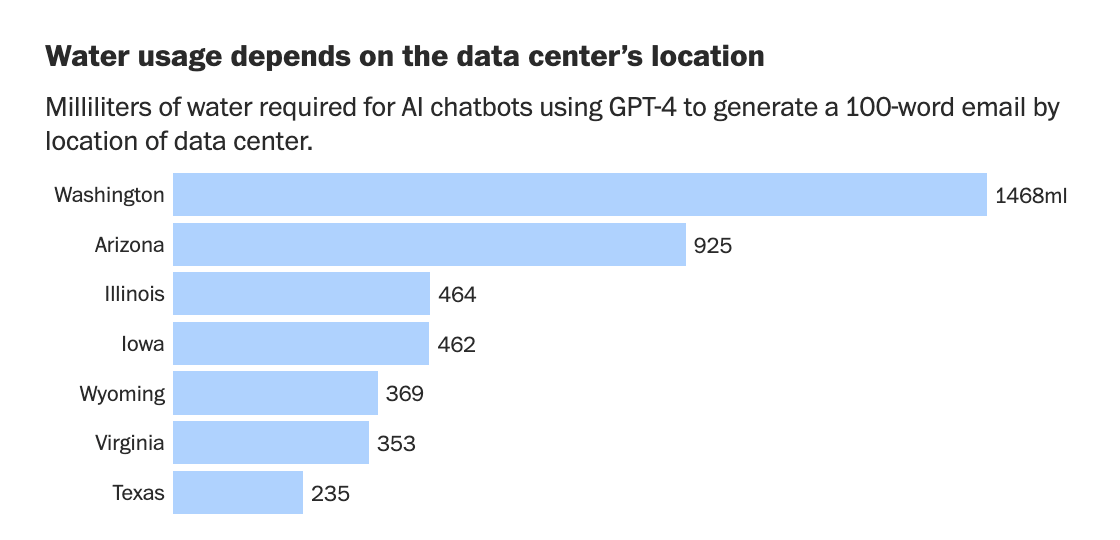
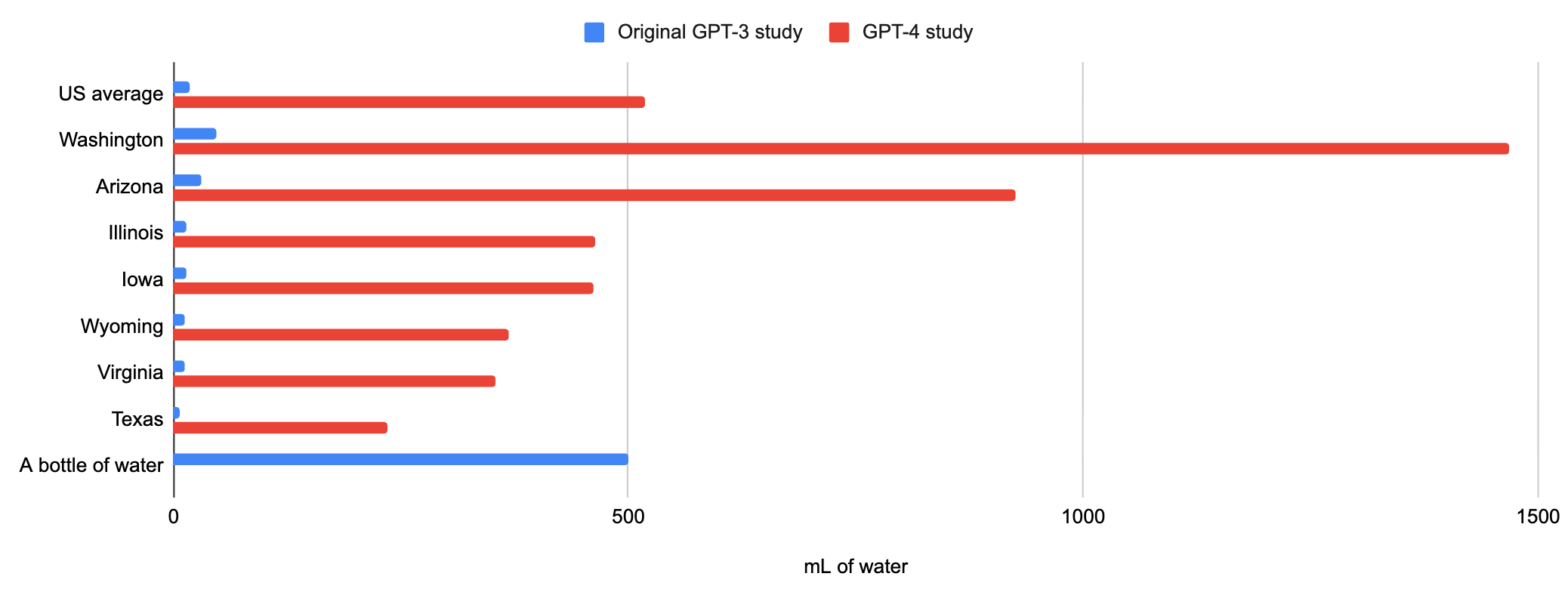
So the claim “AI uses a bottle of water per 100 word email” is based on the estimate that GPT-4 would require 140 Wh to write this email.
140 Wh per prompt is wildly, wildly unrealistic, and fails multiple basic sanity checks:
The servers GPT-4 was running on were designed to handle lots of prompts at once, and drew 10 kW of power. 140 Wh implies that a single prompt would take up the entire server for 50 seconds. In reality, lots of prompts are handled by these servers and only take a few seconds each to answer.
Ren’s estimate is orders of magnitude larger than any other estimate given for similar models. Compare it to EpochAI’s estimate from a few months later:
Epoch’s absolute maximum input query is still over 3 times smaller than the number Ren estimated for GPT-4 handling a single 100 word email. Other estimates fell in a range, but never rose above 3 or 4 Wh.
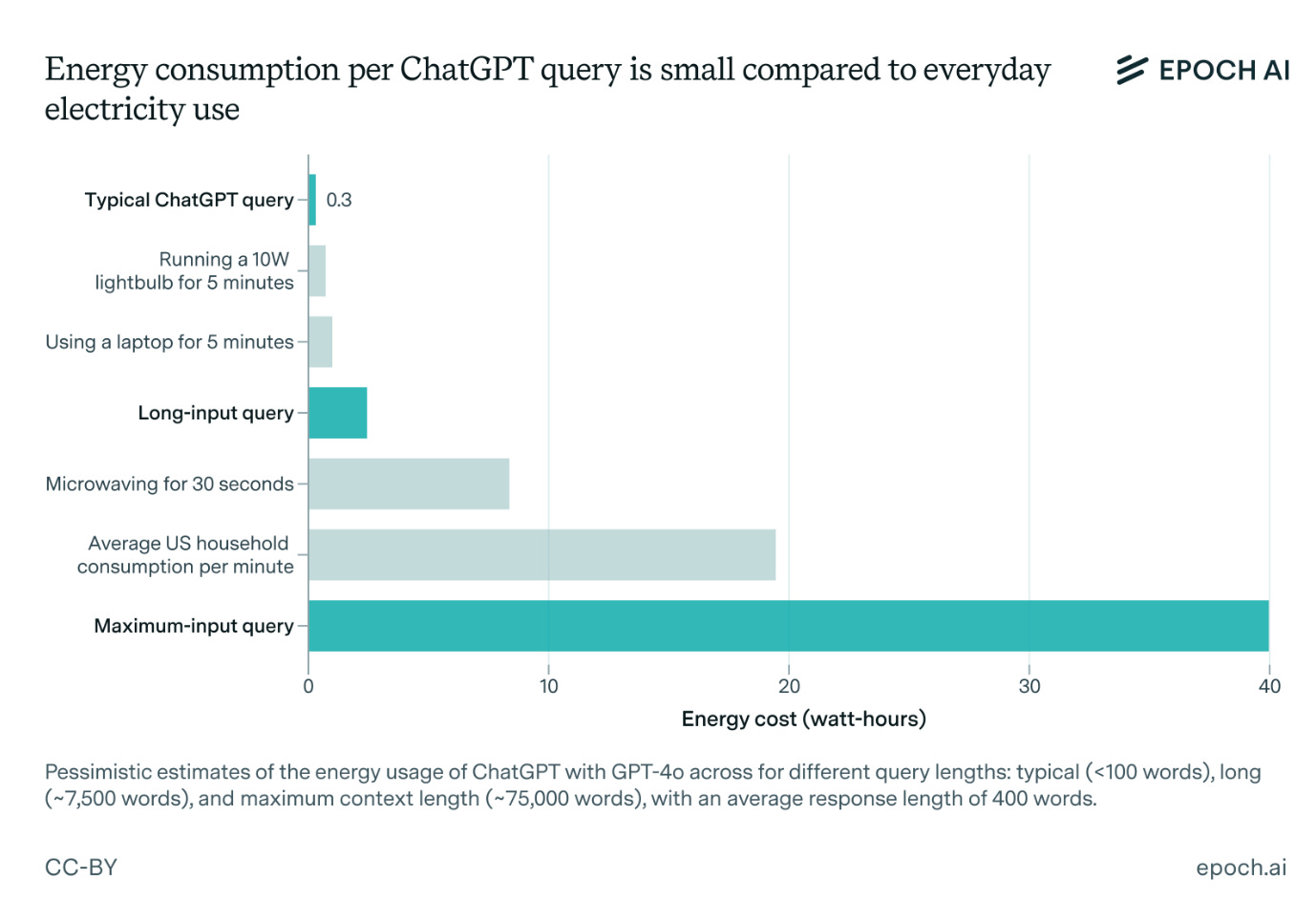
So where did this number come from?
How I think Ren got 140 Wh
Ren never gave a methodology. But I think I figured out what happened.
Ren appeared on the podcast Policy for the Planet, and said this about GPT-4:
What about bigger model like GPT-4? Because although nobody really knows the exact size, but it’s commonly believed to be 1.8 trillion parameters. Based on some interpolation, because all we know is the energy consumption for some small open source models. So we have to do some interpolation for those bigger models. So based on this interpolation, the GPT-4, if you write two emails using GPT-4, the amount of energy could be enough to drive a Tesla Model 3 for one mile.
A Tesla Model 3 uses about 273 Wh per mile. Divided by two emails is about 137 Wh per email, which rounds exactly to WaPo’s 140 Wh. So we know that he interpolated from a rumored 1.8 trillion parameter count of GPT-4, using what he knew about small models.
Later in the interview he clarifies which small model specifically he’s interpolating from, and how long the emails are:
Just to give you a context, if you write two medium-length emails, let’s say 100 to 200 words emails, just two emails, the amount of energy required to write two emails using Llama-3-70B is enough to give you a full charge on your iPhone 16 Pro.
So he’s assuming each email is 100-200 words, and is thinking about this in terms of the model Llama-3-70B.
A few months after this Washington Post article, Ren and a team published a paper where they estimated that the same model (Llama‑3‑70B) used 17 Wh to write 500 words. If we take the middle of his 100-200 word email range, 150 words, we get the cost of writing an email using Llama-3-70B as 17 x 150/500 = 5.1 Wh. 2 x 5.1 is 10.2 Wh, close to the iPhone 16 Pro’s 13.86 Wh battery. If you assume we have a 200 word email and scale up energy linearly with words, this comes out to 13.6 Wh, almost exactly the full charge of the phone.
He says in the interview that he just interpolated from a smaller model’s parameter count and GPT-4’s reported parameter count to estimate how much energy it used. The “70B” in the Llama model name means it has 70 billion parameters. He said GPT-4 has 1.8 trillion parameters. So this means Ren believes GPT-4 is 25.7 times as large as the Llama model he looked at, and therefore uses 26 times as much energy to do the same thing. 5.1 Wh to write an email times 26 is 133 Wh, pretty close to the 137 Wh for driving the Tesla, and the 140 Wh the Washington Post used. I’m pretty sure this is how he got his estimate for how much energy a GPT-4 prompt used.
It seems like he might have given the same “100 to 200 word” range, and said something like “GPT-4 can use 140 Wh to write a 100-200 word email” and the Washington Post authors didn’t want to constantly say the full range and just rounded down.
Stacking errors
This was not a reasonable way to get the estimate, for a few reasons that stack together.
GPT-4 was likely a mixture of experts model, so the active parameters were way lower
While GPT-4’s exact architecture has never been confirmed by OpenAI, by the time this article came out, the best reporting on it we had (a July 2023 leak detailed by Dylan Patel at SemiAnalysis) said GPT-4 was a “sparse mixture of experts” model, which means that most of its parameters wouldn’t be active (and therefore not using energy) for a given token. GPT-4 was rumored to have 16 “expert blocks” that each had about 111 billion parameters, and only two would be active for every token generated. It also had 55 billion additional parameters on for attention, something it’d take too long to explain here. This is also where we got the 1.8 trillion parameter estimate in the first place, so Ren had access to the idea that GPT-4 was probably a MoE model. What this means is that when answering a prompt, GPT-4 would only have 280 billion parameters active at any one time, not 1.8 trillion. GPT-4’s energy cost should have therefore only been 4 times as big as Llama-3-70B (because it had 4 times the active parameters), not 26 times bigger as Ren implied.
Thus, Ren’s estimate was likely 6x as large as it should have been, presuming GPT-4 was in fact a MoE model.
The numbers Ren was using for Llama-3-70B were improperly scaled, and from a range of numbers way too high to begin with
The numbers Ren was using for Llama-3-70B were themselves inflated. He said in the paper that the numbers came from a Microsoft research project that was specifically testing how different organizations of AI chips change their energy use. The research tested Llama-3-70B across different arrangements of hardware to see which was most and least energy efficient.
The paper found that energy use ranged from 4.28 Wh per response in the most efficient setup to 6.45 Wh in the least efficient one. The takeaway was that the worst setups waste significant amounts of energy and data centers can save significant amounts of their energy by switching between arrangements as their workloads changed.
These measurements were for medium-length inputs (under 1024 tokens) paired with medium-length responses (under 350 tokens). A 500-word page is maybe 660 tokens, so Ren and his team needed to estimate how much the energy cost would grow for a longer response. They say:
When deployed on Nvidia H100 server clusters utilizing state-of-the-practice techniques, Llama-3-70B consumes about 0.008 kWh on GPUs for producing a long output with over 350 tokens given a medium-length prompt
If you take the energy cost of the most-efficient arrangement for generating 350 tokens and naively scale it linearly with token count, you get 4.28 Wh x 660/350 = 8.07 Wh.
Incorrect scale-up for more tokens
The paper’s own data on the similarly sized Llama-2-70B (note, not 3) model implies that the scale up from 350 to a “long output” would add about 25% more energy. The paper didn’t run Llama-3-70B across different output-lengths, so Llama-2-70B’s energy is the best evidence we have for how energy actually scales with output length on this hardware. But the two models share the same parameter count and architecture family, so the scaling behavior should be very similar.
It’s not clear what a “long output” is, but their “long inputs” are defined as 1024-8192 tokens, as much as 8x the medium input upper bound. The paper sets these thresholds using the 33rd, 66th, and 100th percentiles of lengths from a chatbot conversation, so “long” just means whatever was in the top third of actual conversational outputs. 660 tokens is likely below the average long response, so the energy increase here is probably even less than 25%.
So it seems very likely that the scale up from Llama-3-70B from 350 to 660 tokens should have only involved a 25% energy increase, not a linear scale up with tokens. This would mean the most efficient model going from 4.28 to 5.35 Wh, not 8 Wh.
So this mistake inflated the cost by 1.5x.
A correct scale-up for overhead
Ren’s team’s method for getting from 8 to 17 Wh for the final cost made more sense. They were adding 67% for non-GPU server energy and 17% for data center cooling overhead. These are both reasonable. 8 Wh x 1.67 x 1.17 = 15.63, close enough to 17 Wh for me to not worry about the specifics of how they calculated this.
There’s a possibility that the 17% for onsite cooling cost might have double counted the onsite water cost if Ren included it in his calculation for GPT-4’s energy, but his water cost model is so dominated by offsite water cost of generating the electricity that this one’s safe to ignore.
These numbers were massively overinflated in the first place
There was a much bigger problem with using these numbers though. The Microsoft study setup was way less efficient than how AI companies actually run models. A follow-up paper from Microsoft a year later specifically mentions that research estimates of the kind used in the original paper could overestimate real-world energy use by 4-20 times, because there are a bunch of different ways of saving energy used in cutting edge AI data centers that the research measurements didn’t include.
So that’s another 4x to 20x mistake.
The Washington Post article ran with the low end of Ren’s range of 100-200 words
It seems like Ren had given an estimate for the energy cost of about 150 words, called it a “100 to 200 word” cost, and the Washington Post team might have just ran with the lowest number. Using 150 words for what’s actually 100 words inflates the final cost by 50%, and for much bigger models with much more fixed overhead costs like GPT-4, it’s more reasonable to assume energy costs scale roughly linearly with token count. So the final estimate is probably 50% higher than it should be, so that’s another 1.5x. It’s reasonable to scale energy linearly with tokens here because for a model the size Ren assumed for GPT-4, the per-token cost dominates everything else.
Putting all the errors together
These errors aren’t all perfectly independent, but naively multiplying them together you get 6x1.5x(4x-20x)x1.5 = 54-270x.
Dividing 140 Wh by these gets a final energy cost of GPT-4 of 0.5-2.6 Wh. This is much more in line with other estimates made of short outputs on similar models. Plugging these into Ren’s study gets approximately 0.3-1.4 mL of water per prompt used onsite and 1.8-8.4 mL used offsite (including water evaporated off lakes dammed by hydroelectric plants) for a total of 2.1-9.8 mL per prompt.
So I think the “bottle of water per prompt” number is inflated by somewhere between 50-250 times, and this is before adding the fact that most of this water is offsite, and half of that offsite water is water evaporated off rivers and lakes dammed by hydroelectric plants that would exist with or without the data centers.
If I’m right, this is what’s actually in the “bottle of water”:

While the Washington Post article did make it clear that much of the water measurement was offsite, many viewers who just saw the graphic mistakenly thought the whole bottle of water was used in the data center itself. Correcting for the errors brings the onsite water cost surprisingly close to Google’s published estimate of Gemini onsite water costs per query at 0.26 mL.
This is the most consequential mistake in the history of writing on AI and the environment. To this day, everyday people still look at me like I’m crazy if I say that AI actually does not use a whole bottle of water, and only about a thousandth of that in the data center itself.
After this article was published, social media jumped all over this claim. Hundreds of the most popular short form videos and images ever made about this topic were about the bottle of water per email claim. This is one of the most popular TikToks on ChatGPT and the environment ever, and concludes with saying each prompt uses a whole bottle of water, which is why you shouldn’t use it. It spread like wildfire and cemented itself in everyday people’s understanding of AI.
It appeared in so many news articles about AI:
Sept 19, 2024 -TechRepublic: “Sending One Email With ChatGPT is the Equivalent of Consuming One Bottle of Water” (Sept 19, 2024)
Sept 19, 2024 - Tom’s Hardware: “Using GPT-4 to generate 100 words consumes up to 3 bottles of water — AI data centers also raise power and water bills for nearby residents”
Sept 21, 2024 - Futurism: “The Environmental Toll of a Single ChatGPT Query Is Absolutely Wild” ()
Sept 19, 2024 - Water Education Colorado: “Briefly: A bottle of water per email”
Nov 29, 2024 - Engineering & Technology Magazine (IET): “ChatGPT consumes one 500ml bottle of water per 100-word request, according to research”
Jan 16, 2025 - Snopes: “AI’s Impact on the Environment, Explained” ()
EVEN SNOPES GOT TRICKED!!
Feb 12, 2025 - Fortune: “California wildfires raise alarm on water-guzzling AI like ChatGPT”
Jan 22, 2026 - Business Energy UK: “ChatGPT Energy Consumption Visualized” ()
Feb 27, 2026 - Katie Couric Media: “How Much Water Does ChatGPT Use? Calculate Your AI Footprint”
Feb 11, 2026 - Newsweek: “Backlash Mounts Over AI Caricature Trend”
EESI (Environmental and Energy Study Institute): “Data Centers and Water Consumption”
This seems to be where everyone’s idea that chatbots use crazy amounts of water per prompt came from. It’s crazy that this is basically all coming from a one-off napkin math estimate that naively scaled energy with parameter count using a baseline model in a completely different situation.
I'm continually impressed by how far you're willing to run to not just disprove, but fully model the mistakes of your adversaries.
If only the world would reward that effort with some public understanding...
Thank you for the analysis.
I think the 'bottle' part of the statement hits hard too. Normally we measure water in litres, but by framing it as a wasted bottle of water, people are prompted to imagine the wasted plastic too. A bottle of water sounds far more polluting than 5 seconds of running a shower.